Meta acaba de predecir la estructura de 600 millones de proteínas .
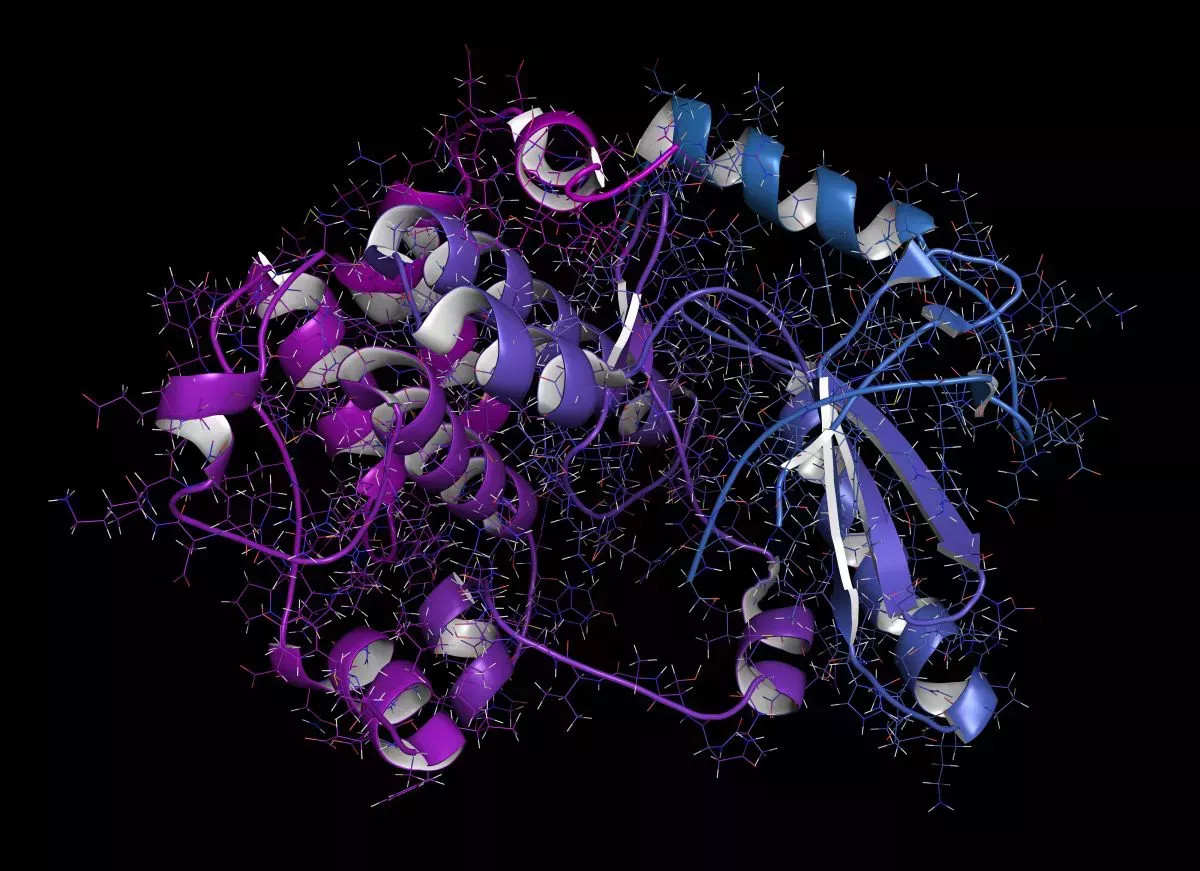
Científicos de Meta, la empresa matriz de Facebook e Instagram, han utilizado un modelo lingüístico de inteligencia artificial (IA) para predecir las estructuras desconocidas de más de 600 millones de proteínas pertenecientes a virus, bacterias y otros microbios.
El programa, denominado ESMFold, utilizó un modelo diseñado originalmente para descifrar lenguas humanas con el fin de hacer predicciones precisas de los giros y vueltas que toman las proteínas y que determinan su estructura 3D. Las predicciones, que se compilaron en el Atlas Metagenómico ESM de código abierto, podrían utilizarse para ayudar a desarrollar nuevos fármacos, caracterizar funciones microbianas desconocidas y rastrear las conexiones evolutivas entre especies lejanamente relacionadas.
La IA DeepMind ha descubierto la estructura de casi todas las proteínas conocidas por la ciencia
Definición y estructura
ESMFold no es el primer programa que hace predicciones de proteínas. En 2022, la empresa DeepMind, propiedad de Google, anunció que su programa de predicción de proteínas AlphaFold había descifrado las formas de los aproximadamente 200 millones de proteínas conocidas por la ciencia. ESMFold no es tan preciso como AlphaFold, pero es 60 veces más rápido que el programa de DeepMind, según Meta. Los resultados aún no han sido revisados por pares.
Científicos de DeepMind ganan un 'Breakthrough Prize' de 3 millones de dólares por una IA que predice la estructura de cada proteína
"El Atlas Metagenómico ESM permitirá a los científicos buscar y analizar las estructuras de las proteínas metagenómicas a escala de cientos de millones de proteínas", escribió el equipo de investigación de Meta en una entrada de blog que acompaña a la publicación del artículo en la base de datos de preimpresión bioRxiv. "Esto puede ayudar a los investigadores a identificar estructuras que no han sido caracterizadas antes, buscar relaciones evolutivas lejanas y descubrir nuevas proteínas que pueden ser útiles en medicina y otras aplicaciones".
Las proteínas son los componentes básicos de todos los seres vivos y están formadas por largas y sinuosas cadenas de aminoácidos, diminutas unidades moleculares que se unen en innumerables combinaciones para formar la forma tridimensional de la proteína.
Conocer la forma de una proteína es la mejor manera de entender su función, pero hay un número asombroso de maneras en que la misma combinación de aminoácidos en diferentes secuencias puede tomar forma. A pesar de que las proteínas adoptan ciertas formas de forma rápida y fiable una vez producidas, el número de configuraciones posibles es de aproximadamente 10^300. El método de referencia para determinar la estructura de una proteína es la cristalografía de rayos X -observar cómo los haces de luz de alta energía se difractan alrededor de las proteínas-, pero se trata de un método minucioso que puede tardar meses o años en producir resultados, y no funciona para todos los tipos de proteínas. Tras décadas de trabajo, se han descifrado más de 100.000 estructuras de proteínas mediante cristalografía de rayos X.
Para encontrar una solución a este problema, los investigadores de Meta recurrieron a un sofisticado modelo informático diseñado para descodificar y hacer predicciones sobre los idiomas humanos, y aplicaron el modelo al lenguaje de las secuencias de proteínas.
"Utilizando una forma de aprendizaje autosupervisado conocida como modelado de lenguaje enmascarado, entrenamos un modelo de lenguaje en las secuencias de millones de proteínas naturales", escribieron los investigadores. "Con este enfoque, el modelo debe rellenar correctamente los espacios en blanco en un pasaje de texto, como "To __ or not to __, that is the ________". Entrenamos un modelo lingüístico para que rellenara los espacios en blanco de una secuencia de proteínas, como "GL_KKE_AHY_G" en millones de proteínas diversas. Descubrimos que de este entrenamiento surge información sobre la estructura y la función de las proteínas."
Para poner a prueba su modelo, los científicos recurrieron a una base de datos de ADN metagenómico (llamado así porque ha sido secuenciado en masa a partir de fuentes ambientales o clínicas) tomado de lugares tan diversos como el suelo, el agua de mar y el intestino y la piel humanos. Al introducir los datos del ADN en el programa ESMFold, los investigadores predijeron las estructuras de más de 617 millones de proteínas en sólo dos semanas.
Son más de 400 millones más de las que AlphaFold anunció que había descifrado hace cuatro meses, cuando afirmó haber deducido la estructura proteica de casi todas las proteínas conocidas. Esto significa que muchas de estas proteínas nunca se habían visto antes, probablemente porque proceden de organismos desconocidos. Se cree que más de 200 millones de las predicciones de proteínas de ESMFold son de alta calidad, según el modelo, lo que significa que el programa ha sido capaz de predecir las formas con una precisión hasta el nivel de los átomos.




